The series of pairs is separated by the ampersand, "&" (or semicolon, ";" for URLs embedded in HTML and not generated by a <form>...</form>. See below).」「
This convention is a W3C recommendation.[6] W3C recommends that all web servers support semicolon separators in addition to ampersand separators[9] to allow application/x-www-form-urlencoded query strings in URLs within HTML documents without having to entity escape ampersands.」 W3C がってところが今となっては、かなあ。もちろん立場が違えばセミコロンが解釈できなくて話が通じない相手とはそれまでっていうのが自分のスタンスなんだけど、AtCoder には合わせるしかない。■@2022-03-07 最近 OpenBD のデータが、抜けているというより常に取得できてないなと気がついて見たら、セミコロン区切りのせいでクエリが失敗するようになっていた。ここでもなのか。
no! if U[a,b] の no! を取り除くとダメになるケース(8 4/3 3 3 1 1 1 1 1/1 2/1 3/2 3/7 8)がある。この提出 #29483417 (WA×1) を阻んでいる random_21.txt が同等の(無駄な辺と森化による辺の必要数の減少が相殺する)ケースだと思う。■■■E 問題「Subtree K-th Max」。最近似た名前の問題がありましたね>「Prefix K-th Max」。一読して表現の微妙な変化に気がついたんですよ。ABC234で「K 番目に大きい値」という表現だったものが ABC239 では「
大きい方から Ki 番目の値」になっていた。それが「中途半端な値は見ようによって大きい値でもあるし小さい値でもある。自分に言わせればそれは単に「大きい方から K 番目の値」なんであって、大きい値でも小さい値でもない」をうけての変化だとは思わないけど、自分が理解しやすい表現になっていたのは間違いない。それなのに AC 前の5分で 2 WA しました(WA、WA、AC)。読んで、表現の変化にも気がついて、でも結局間違えるんだ。手癖で書いてるってことなんだろうなあ。■「AtCoderの公式生放送「あーだこーだー」 第51回 - YouTube」を聞いていると E 問題「Subtree K-th Max」に関連して Wavelet Matrix の単語が何度も聞こえてきた。E 問題では K の上限が意図的に小さく抑えられていて、ここを突破口にして解けよ、というヒントがあからさまだったけど、さもなければ Wavelet Matrix を使って解くことになったらしい。Crystal では通ってるぽいのに Ruby で TLE になるの悔しいよね。通ってほしい。参考図書『[単行本] 岡野原 大輔【高速文字列解析の世界――データ圧縮・全文検索・テキストマイニング (確率と情報の科学)】 岩波書店』は持ってるだけは持ってる。WEB+DB PRESS vol.42 の記事を読んで著者の名前を覚えていた。
プラスアルファで悉くつまずいて AC に辿り着けない」とか「
区間の左右端と節約回数の上下端が off-by-one エラーを誘発しやすい感じ(ドツボにはまった経験から書いています)」を今日も再現しておかしくはなかった。早々に愚直解とランダム入力を組み合わせてダメケースの発見に努めることができたのが運命の分かれ目。終了3分前の提出 #29545375 (AC)。これ水 diff なんだって。全く同じではないにしてもかつての黄 diff が形無しですよ。
1ビット分誤差が入るからダメって?」に対するツッコミにならないのでは?という疑問には、それはそうと思う。誤差が大きすぎるという納得はわからない。
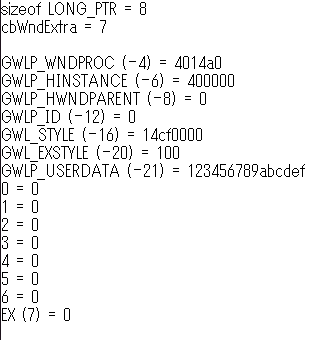
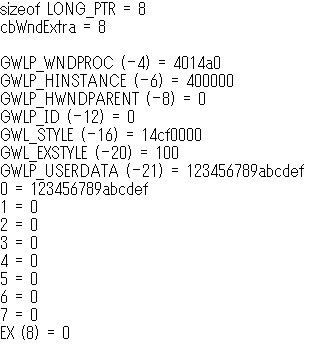
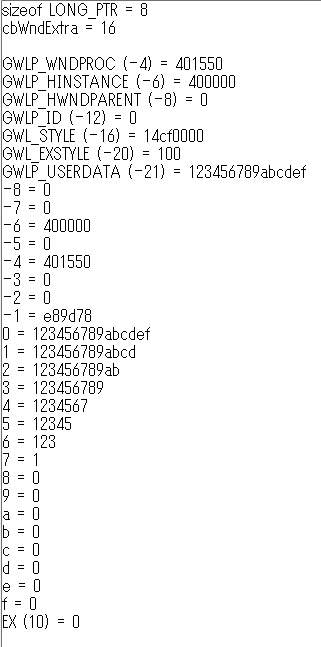
Valid values are in the range zero through the number of bytes of extra window memory, minus the size of a LONG_PTR」を読み間違えていた。有効な値は 0 から cbWndExtra までと 0 からマイナスポインタサイズまでではなく、0 から「cbWndExtra マイナス ポインタサイズ」までだった。えええええ、そこにカンマを入れる? そしてカンマひとつでここまで勘違いをひきずるか>自分。■オンラインでは見つけられなかったけど PC 内に日本語訳を見つけた。「
nIndex 取得する値に 0 から始まるオフセットを指定します。有効なオフセットは、0 から拡張ウィンドウメモリのバイト数 -8 までです。たとえば、拡張メモリが 24 バイト以上ある場合、16 を指定すると、3 番目の整数値が取得できます。その他の値を取得するときは、次のいずれかの値を指定します。」 具体例まで追加していい仕事してますよ。見つからんかったけど。
最終更新: 2022-02-11T22:02+0900
先日解いていた「JOIG 2021/2022 本選競技課題」(テストケースのダウンロードができる) の F 問題へのこの提出に関して>20220129p01.05。
Hash#shift を意味がある限り繰り返したあとで Hash#clear を呼ぶようにしている(25 行目)。shift は破壊的なメソッドだから shift を十分に呼び出した後の Hash は空になっているはずで、clear を呼ぶ意味はなさそうに思える。それでも呼ぶようにしているのは、これがないとテストケースの in/05-01.txt に限ってスクリプトの応答がなくなって TLE になると思ったから。少なくともローカル Windows 環境では Ruby-2.7 と Ruby-2.5 で止まる。Ruby-1.9 は平気。他のテストケースでは止まらないけど、問題のケースでは必ず止まる。止まるタイミングはバラバラだけど、いずれも Hash への代入で止まっているようだった。
再現スクリプトはこんな感じ(これを見つけたから日記に書いている)。他所で再現するかは、どうでしょうね。
Many = 100 # 10 回では少ない。テキトーに大きく。
Some = 100 # ウチでは 30 回目までは到達しない。
# ウチの Ruby-2.5: ruby 2.5.5p157 (2019-03-15 revision 67260) [x64-mingw32]
# ウチの Ruby-2.7: ruby 2.7.1p83 (2020-03-31 revision a0c7c23c9c) [x64-mingw32]
Some.times{|some|
warn "#{some} begin"
hash = {}
Many.times{
some.times{|j|
k = Random.rand 0..Many
hash[k] = 1 # maybe hang
}
0 while hash.shift
}
warn "#{some} end"
}
warn :exit
Ruby-2.5 と Ruby-2.7 では "N begin" (N は 20 前後) を表示して止まる。2.5 より 2.7 の方が早く止まるという傾向はあるけど、具体的な回数にはバラツキがある。それはまあ乱数を使ってるからだと思うけど、ハッシュのキーを k に代えて j にしたり、シャッフルした順列にしたりすると止まらなくなるので(正常動作)、乱数は外せない。
こういう Issue「Bug #17779: 特定の順序でHashのkeyを削除した場合に Hash#first が遅くなる - Ruby master - Ruby Issue Tracking System」を思い出したけど、全然関係はなさそう? 全然わからない。
AtCoder のコードテストを使わせてもらったら(目的外失礼)、こういう結果。AtCoder の Ruby も今のバージョンは 2.7。
| 終了コード | 9 |
| 実行時間 | 10501 ms |
| メモリ | 9112 KB |
標準エラー出力は 30 begin で途切れている。完走しても 10 秒もかかるはずないから、ハングして実行を打ち切られたのだと思う。コードテストとジャッジサーバーが同じだとして、ジャッジサーバーのスペックはこう>Linux ip-***-***-***-*** 4.15.0-1041-aws #43-Ubuntu SMP Thu Jun 6 13:39:11 UTC 2019 x86_64 x86_64 x86_64 GNU/Linux*⁑。
Ruby-3.1 が「ウチの Ruby」に今日加わりました。大体ループの 20 から 30 回目で止まるんだけど、弾みで 2 回だけ完走したりもした。
パラメータが2つもあると面倒なので。
改訂するにあたって予想外に止まらなくなったりした(正常動作)のを通して、たぶん直接的な原因もわかった。
# ウチではだいたい 20 から 30 回で "empty?: true" を最後にして止まる。
# ウチの Ruby-2.5: ruby 2.5.5p157 (2019-03-15 revision 67260) [x64-mingw32]
# ウチの Ruby-2.7: ruby 2.7.1p83 (2020-03-31 revision a0c7c23c9c) [x64-mingw32]
# ウチの Ruby-3.1: ruby 3.1.0p0 (2021-12-25 revision fb4df44d16) [x64-mingw-ucrt]
H = {}
100.times{|n|
while H.size < n
k = Random.rand 0..1<<30
H[k] = 1 # たぶんここで止まる。
end
warn "size: #{H.size} before shifting."
H.shift until H.empty?
raise if H.shift # no exception. だけど Hash が空になった後の shift が後でハングをひき起こす?
warn "empty?: #{H.empty?}"
}
warn :exit
Hash を空にする方法として 0 while H.shift を選ぶとその後の Hash#[]= でハングするが、Hash を空にする方法として H.shift until H.empty? を選ぶとハングしなかった。条件を揃えていくと、Hash#empty? が作用してハングを回避しているのではなく、Hash が空になったあとの Hash#shift がハングをひき起こしているようだった。ちなみに Hash#clear にハングを回避する効果があるらしいのは、JOIG の問題への提出で確認済み(とはもう書いた)。
投稿して次に見たときにはすべてが終わっていた。早いぜ。
こういう仕組みだったようです。
メモ:entries_bound は使用中のビン(DELETEDになったビンを含む)の数に(ほぼ)対応していて、これをみてテーブルをリビルドしている(rebuild_table_if_necessary)。空のハッシュに対する Hash#shift はなぜか entries_bound を 0 にしているので、リビルドすべきタイミングを逃し、ビンがすべて使用中になった状態で空きビンを探そうとするので無限ループに陥っていた(find_table_bin_ind)。
{kind=link}
{kind=link}
{kind=link}
{kind=link}